1. Nagaraja, C. H., Brown, L. D., & Wachter, S. M. (2010). House price index methodology. Pre-Print/Working Paper.
2. Clapp, J. M., Giaccotto, C., & Tirtiroglu, D. (1991). Housing price indices based on all transactions compared to repeat subsamples. Real Estate Economics, 19(3), 270–285.
4. Gatzlaff, D. H., & Haurin, D. R. (1997). Transactional case-shiller vs. Hedonic zillow housing price indices (HPI): Different construction, same conclusions. Journal of Real Estate Finance and Economics, 15(2), 169–187.
5. Rzepczynski, M., & Feng, W. (2025). Transactional (case–shiller) vs. Hedonic (zillow) housing price indices (HPI): Different construction, same conclusions? Real Estate, 2(4), 19.
6. Gudell, S. (2017). Accuracy in context: Why zillow’s case-shiller forecast is so dependable. In
Zillow.
https://www.zillow.com/research/zillow-case-shiller-forecast-14308/
7. Pesquisa Econômica Aplicada (FIPE), I. de, & Imóveis, Z. (2011). FipeZap index – methodology. FIPE – Fundação Instituto de Pesquisas Econômicas.
9. Alharbi, F. R., & Csala, D. (2022). A seasonal autoregressive integrated moving average with exogenous factors (SARIMAX) forecasting model-based time series approach. Inventions, 7(4), 94.
10. Taylor, S. J., & Letham, B. (2018). Forecasting at scale. The American Statistician, 72(1), 37–45.
11. Omotoye, E. A., & Rotimi, B. S. (2025). Stationarity in prophet model forecast: Performance evaluation approach. American Journal of Theoretical and Applied Statistics, 14(3), 109–117.
12. Hyndman, R. J., & Athanasopoulos, G. (2018). Forecasting: Principles and practice. OTexts.
13. Hyndman, R. J., & Athanasopoulos, G. (2018).
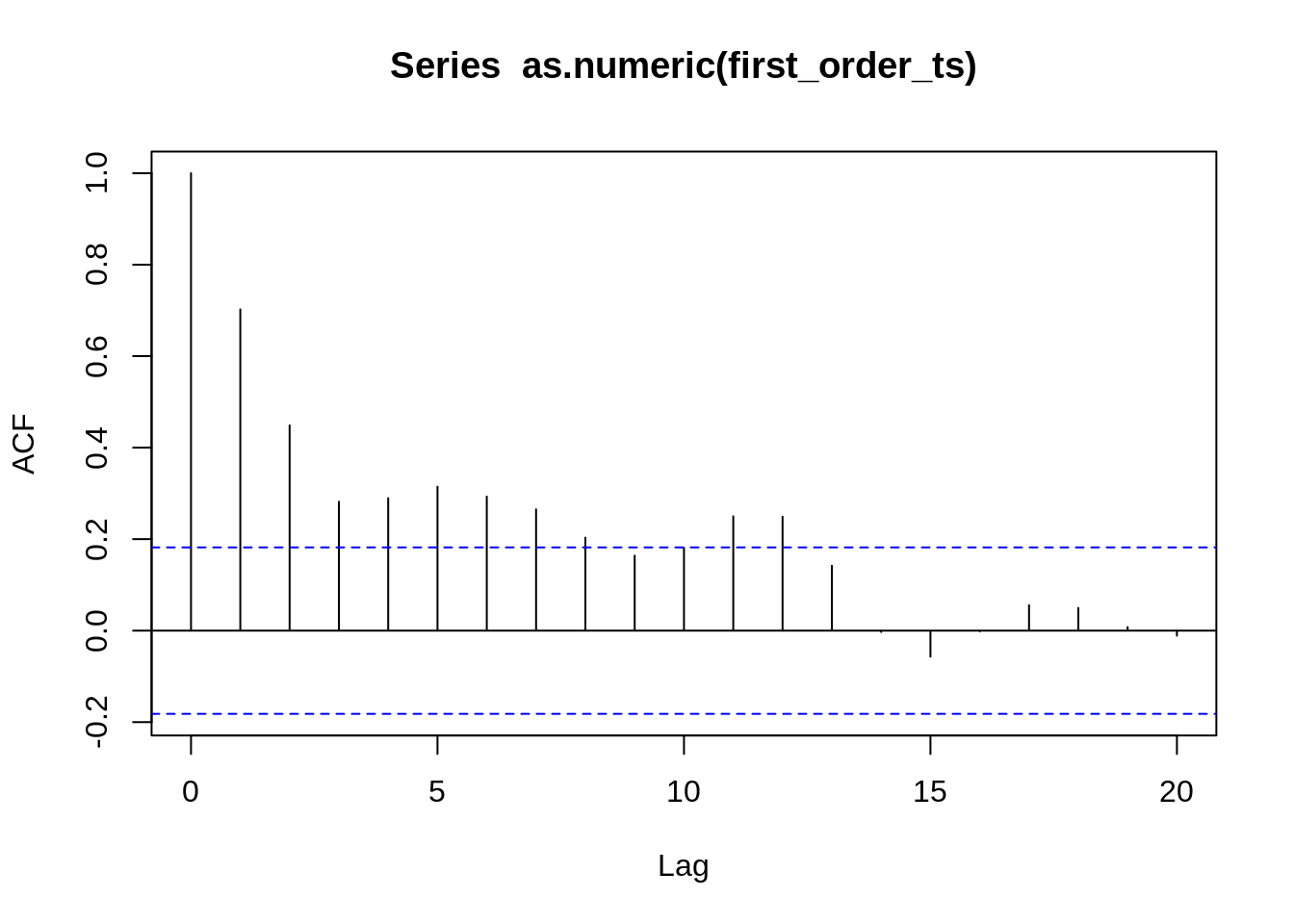
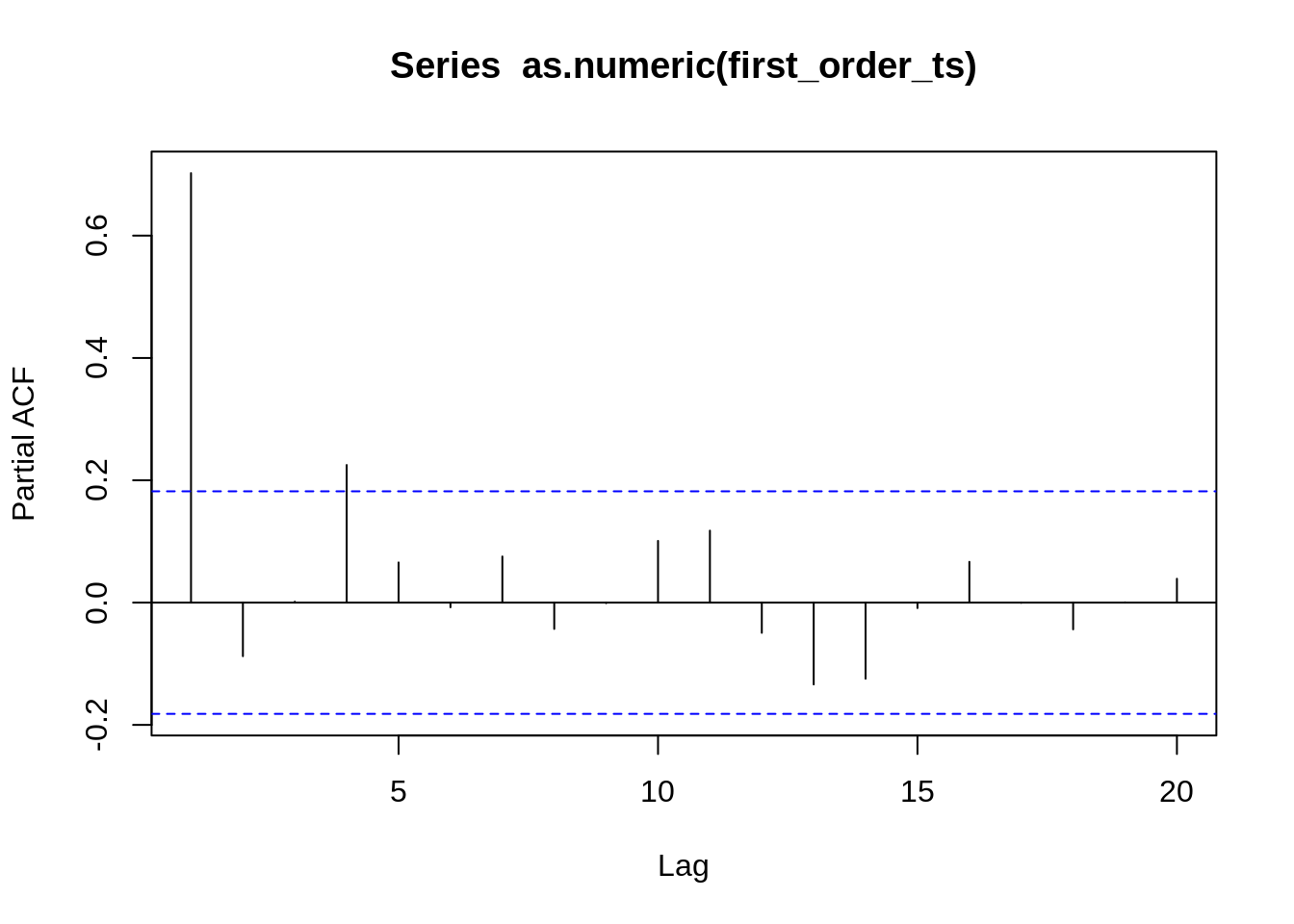
8.1 stationarity and differencing | forecasting: Principles and practice.
https://otexts.com/fpp2/stationarity.html
14. Menculini, L., Marini, A., Proietti, M., Garinei, A., Bozza, A., Moretti, C., & Marconi, M. (2021). Comparing prophet and deep learning to ARIMA in forecasting wholesale food prices. Forecasting, 3(3), 644–662.
15. Vuong, P. H., Phu, L. H., Van Nguyen, T. H., Duy, L. N., Bao, P. T., & Trinh, T. D. (2024). A bibliometric literature review of stock price forecasting: From statistical model to deep learning approach. Science Progress, 107(1), 00368504241236557.
16. Kendall, M., & Stuart, A. (1983). The advanced theory of statistics, vol. 3: Distribution theory (pp. 410–414). Griffin.
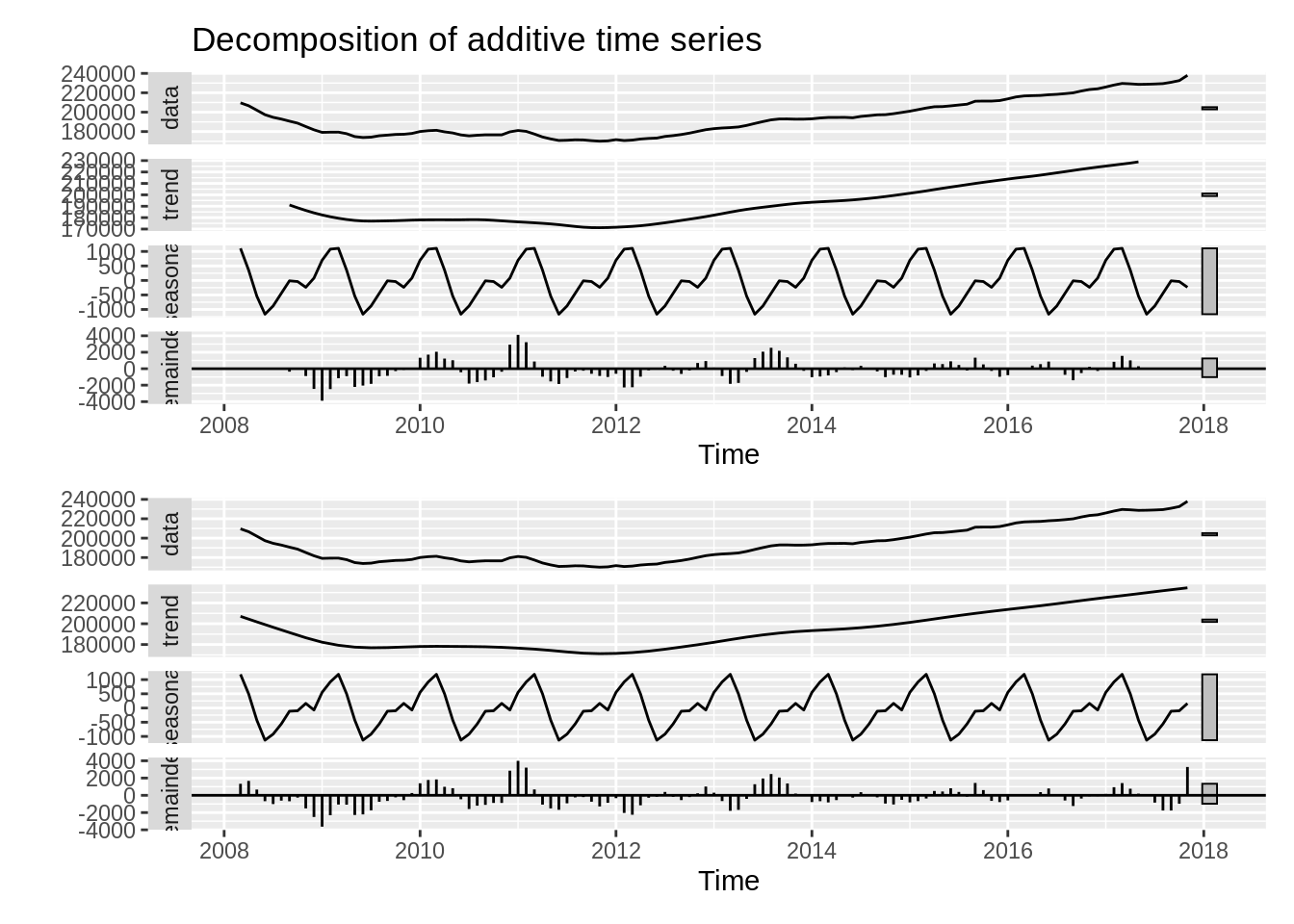
17. Cleveland, R. B., Cleveland, W. S., McRae, J. E., Terpenning, I., et al. (1990). STL: A seasonal-trend decomposition. J. Off. Stat, 6(1), 3–73.